


Nichebench - Benching AIs vs Drupal 10-11
Introduction
Finally, this article took me ~ 2 months to write-up 📅 - mostly because coming up with Nichebench, creating test-cases and running slowly the tests against many existing LLMs.
Let’s start with this - not all LLMs are created equally. The data they are trained on, the formatting of the data, the labelling, the used underlying architecture and many other parameters - heavily influence the final result. Some LLMs might be good at coding 🧑💻, but when prompted about Drupal 10 or Drupal 11 implementation, might creep-out some Drupal 7-flavor solutions - or plainly hallucinate some slop as a reply 😵
Most of us get around these issues, by just throwing more money at this problem - i.e. picking Claude Sonnet 4 (or Opus) - or using up Github Copilot’s paid credits.
Very few of us play with smaller LLMs (be it via OpenRouter, Together.AI, groq or Ollama) - and that’s understandable, because after a few tries, you’d quickly realize that they are performing pretty poorly - specifically in the Drupal 10/11 setting.
You normally end-up re-prompting and explaining in-details what you want the AI Agent to achieve - constantly thinking “wouldn’t it be faster if I’d just do it myself?”. And, you continue re-prompting, like "Do it, or..."

As a part of my experiment (started in this article) - I want to fine-tune a niche-LLM, one that would focus on Drupal 10/11 knowledge and recent best-practices, and see if I could reach (or even outperform) current SOTA models.
The next stepping stone on this journey is to find a good, solid, open-weight model to build upon - enter Nichebench by HumanFace Tech👇
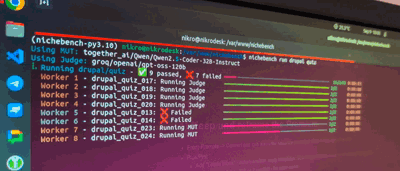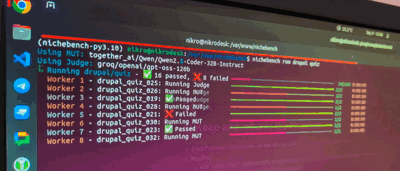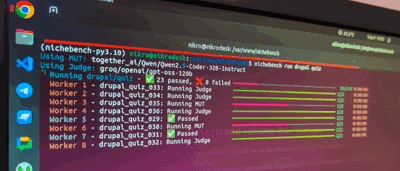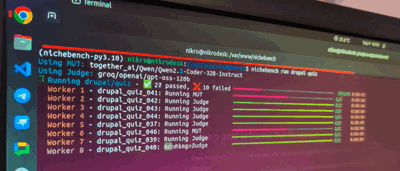
Introducing Nichebench
To test how well AI models know Drupal 10-11 - we’ve cooked 🧑🍳 Nichebench.
I originally wanted to base it on LightEval - but quickly realized that LLM-as-a-Judge multi-turn complexity, didn’t allow me to proceed as I wanted, so, instead, I embraced DeepEval.
Using DeepEval offered us:
- Consistency - it’s a relatively simple-to-embrace framework, and keeps things flexible, but also enforces consistency - in terms of how the tests should be written and evaluated.
- Future-proofing - now, I focus specifically on Drupal knowledge, but I’d like to run in parallel other tests on the model (MMLU, etc) - and there are many baked-in tests (Task Completion, Tool Correctness, etc.).
- Parallel task execution - allows us running concurrent tests - to speed things up.
Although I didn’t stay 100% loyal to the framework → I wanted to have my own formatted outputs / CLI tool, so I had to go ‘around’ the traditional deepeval CLI tool (which handles concurrency and other stuff) - but it’s ok (maybe I’ll reverse this in the future).
Nichebench so far supports 2 types of tests (there’s a 3rd but I’ll ignore it for now): quiz & code_generation.
Quizzes are simple - they usually have: A, B, C, D, E, F answers - and we STILL use LLM-as-a-Judge to verify the answer. Why - some LLMs might give random explanation or blabber, and then say “Okay, so, saying all that - I think the actually answer is A” - and I’d like to have an LLM to figure that out.
Code Generations are a bit more complex - they have a detailed system prompt, then a context of a task at hand, then what’s expected from the MUT (model under testing), then the model completes the end-to-end implementation and forwards this to LLM-as-judge (usually gpt-5@medium in my case) - and the Judge also sees a list of criteria & judge hints - what to look for and why.



⚠️ NOTE: I didn’t ship the actual quiz & code tasks as a part of this repo, because I don’t want newer models to use my questions / answers for their training (so the folder will be empty) - but you can ask me and I can add you to the private repo, if you’re interested (or if you wish to contribute).
Results: Drupal Quiz
Here’s the result - top to bottom (best to worst):



I did test a lot of models - because in general, this test is relatively fast and cheap (unless it’s a reasoning model). You’ll see that some SOTA models didn’t get 95-100% but 90-91% - and that’s fine. It’s not about absolute perfect score, it’s about relative score - that’s why I tested also proprietary SOTA models: gpt-5 and claude sonnet 4.
My take-away from this test:
- phi4:14b from Microsoft - scored 88%, that was impressive!
- gpt-oss-120B - scored 90% (and 20B - 80%)
- devstral:24b - scored 88%
- qwen3-coder-30b-a3b - scored 86%
Some models scored better than others, also because of recency - some tests (both Quiz & Code Gen) that I have include relative fresh Drupal 11 APIs (but a small %). Sure, that might NOT be relevant as we’ll use fine-tuning to solve those - but wouldn’t we rather start with a model that already is better at some of those?
Results: Drupal Code Generation
Here’s the result - top to bottom (best to worst):



Now this test tells a totally different story. Important to note - this is NOT agentic, this is 1 time output (multiple file changes in 1 textual output) test.
These tests run long-time and are pretty expensive. For reference - GPT-5@Medium (judged by GPT-5 itself) scored 75%. I think Claude Sonnet 4 or GPT-5@High would probably get 80-90%.
And now let’s switch focus back to our open-weight models → and the GAP is HUGE. Take-aways:
- gpt-oss-120B - is the highest, hit 40%
- gpt-oss-20B - is the next-best, reached 32-35% ← a really good candidate! 👑
- phi4:14B - scored only 22-23%, disappointing
- qwens: qwen3-32b - scored very well - 32%, while qwen3-coder-30b-a3b - 27%
I know people complained about gpt-oss models NOT being amazing or up to their expectations - but somehow these models did pretty well on my tests.
One IMPORTANT thing to note here - gpt-oss models were pretty weak generating complex properly escaped function calls (JSONs), that’s a normal thing for smaller models but somehow it really sticks badly in gpt-oss models (120B ofc performs way better, but even it screws up)
RAW results can be found in this spreadsheet 📊.
Analysis, Picking Finalists
After these tests - heavier relying on the results of code generation tests → here’s the analysis of 4 smallish LLM models.
| Model | Arch | Context (native) | License | Tool Use | JSON/YAML/XML Gen | Coding Specialization |
|---|---|---|---|---|---|---|
| GPT-OSS-20B | MoE | 128K | Apache-2.0 | Native function calling, browsing, Python tools — but flaky reliability (JSON/tool-call errors reported) | JSON/YAML supported, but frequent parsing errors 👎 | Generalist; decent coding & reasoning, not coding-specialized |
| Phi-4 (14B) | Dense | 16K (32K reasoning variant) | MIT | Supports function calling (basic) but limited depth; better in small iterative tasks | Good structured extraction, less reliable for complex JSON | Strong at math & reasoning, weaker at repo-scale coding |
| Qwen3-32B | Dense | 128K | Apache-2.0 | Standard tool calling, reliable & stable | JSON/YAML generation very consistent 👑 | Balanced — not coding-only, but very stable all-rounder |
| Qwen3-Coder-30B-A3B | MoE | 256K 👑 (up to 1M with YaRN) | Apache-2.0 | Advanced agentic tool use (XML format for calls; more reliable on quantized runs) 👑 | Excels in structured output for dev workflows (JSON/YAML/XML) 👑 | Specialized for repo-scale coding, strong at multi-file agentic workflows 👑 |
👉 Another ‘down-fall’ of Phi-4 is its tiny context window, and basic tool-use (less agentic) than newer models.
👉 GPT-OSS-20B still looks good in many regards - but we WILL need to address the JSON/XML/YAML serialization issue. Bad side of it is that it’s generalist - but even so it outperformed qwen3-coder-30b-a3b in both test-types.
👉 I like both Qwen3 models but for different reasons - MoE flavor is code-specific, agentic → I’d expect exceptional tool-use, serialization and other aspects (also a huge context-window); while the dense one generally outperforms in many regards, even if it’s generalistic.
—


%20.webp)
I also favor a bit GPT-OSS-20B because of its guardrails 🛡️, I know OpenAI team invested a lot into it, so per general I’d feel safer playing with it. Another reason is its huge popularity (at least for now) - which means I could throw my LoRAs onto almost any server and have it running - and at very fast speeds. And finally, I also want to consider LATER the option of transferring the fine-tuning to its larger brother: 120B.
And, here's a full video covering the article:
Next Steps
Building on top of Fine-tuning article - next step would be to generate proper synthetic data, I’m talking about 10k-20k of proper technical Drupal-related tasks and solutions, properly described, annotated, labelled and what not.
And then, we start cooking a proper NicheAI - Drupal AI LLM, and see if we can reach SOTA-quality level.
Here’s what to expect:
- 🧪 Hardware - we’ll dive into the building process of the best cost-optimized AI-rig at home, capable of fine-tuning serious models, all under $2000 🤯.
- 🧪 Generating proper dataset - how can we generate a large-enough and good-enough dataset for our fine-tuning process?
- 🧪 Niche LLM models - how we can improve existing coding models, to be incredibly fluent in a niche programming language or framework - looking at you, Drupal 😏
- And much more 😀
If these articles are useful and/or entertaining for you - please consider supporting the effort ☕ via Ko-Fi donations 👇
💡 Inspired by this article?
If you found this article helpful and want to discuss your specific needs, I'd love to help! Whether you need personal guidance or are looking for professional services for your business, I'm here to assist.
Comments:
Feel free to ask any question / or share any suggestion!